A common code smell that attracts my attention right away is when I see an explicit conversion being done, typically done using CAST or CONVERT.
However, implicit type casting can be worse and is typically not readily apparent.
During code reviews I found some instances where the code would actually just error trying to convert text to an integer, but that will normally be caught in some stage of testing.
For this article I want to briefly discuss the hidden cost of the implicit conversion.
I do not want to go into the details of data type precedence in this article so I will just say that you want:
- Parameters in where clauses should be the same data type that they are being compared to
- Fields used to join tables should be the same data type.
Design Considerations
When we do not adequately define our data structure up front you can end up with queries where you have to jump through hoops in order to get something to perform.
For example, CLABSI has many stage tables where PATID is defined as different types nvarchar(255) or varchar(128) or BIGINT this causes performance degradation and coding problems.
When building our data model we need to define what the data type should be and use that everywhere instead of letting different source queries, random guesses, or SQL defaults define them.
The Optimizer
When two different data types need to be matched the query optimizer will have to perform a CONVERT_IMPLICIT operation on every row, leading to no indexing being considered for that row.
The larger the table gets the worse the performance will get.
The performance can be very bad the larger the table gets.
How can we find them?
Luckily database projects can help you find these problems fairly easily using the code analyzer.
To turn on the Code Analysis for every build…
- Right Click on the Project Name
- Select Properties
- Select “Code Analysis”
- Enable code analysis on build
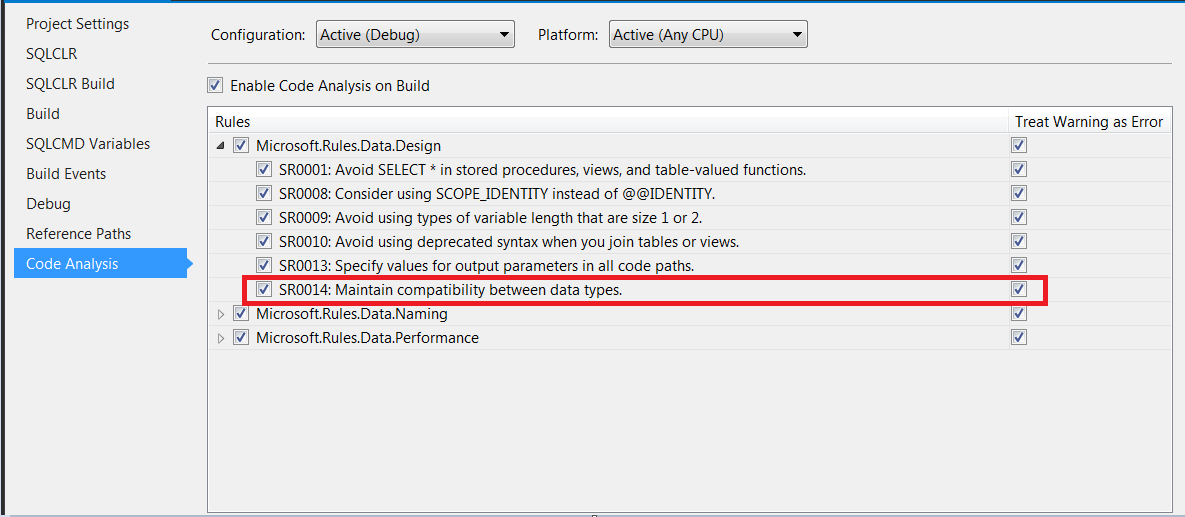
Most new projects will have the code analyzer rules all turned on and treated as an error so they will have to be manually suppressed if there is a valid reason for doing so.
However, reverse engineered legacy applications normally have too many violations for us to turn the code analysis on without project work to clean up the code and re-architect certain things.
How do we address them?
This is the million dollar question.
For new development we can typically correct the data model and code before it ships. For legacy applications a decision has to be made to weigh the cost and risks of re-architecting the solution with the benefits. Be careful though because any debt could impact future development.
If you are doing any new development that touches legacy areas that should be changed the issue should be raised again for discussion.
Let me know what you think in the comments below.