Many of the current products we have released into the wild are using an architecture such that the standard product is not tightly coupled with any particular sites custom ETL transforms. We gain many benefits from this approach, such as:
- Improve speed of development by removing number of hard-coded site specific rules within the “standard” product
- Standard product is more easily tested
- Reduced backup time of product data
- Products are easier to support as they work the same everywhere
- And more…
At our recent company all-hands I had a couple requests on how the data actually flowed thru the system. I thought I would outline the current pattern to give people an idea of how it works in its current state.
Below is a summary of the main elements of the pattern.
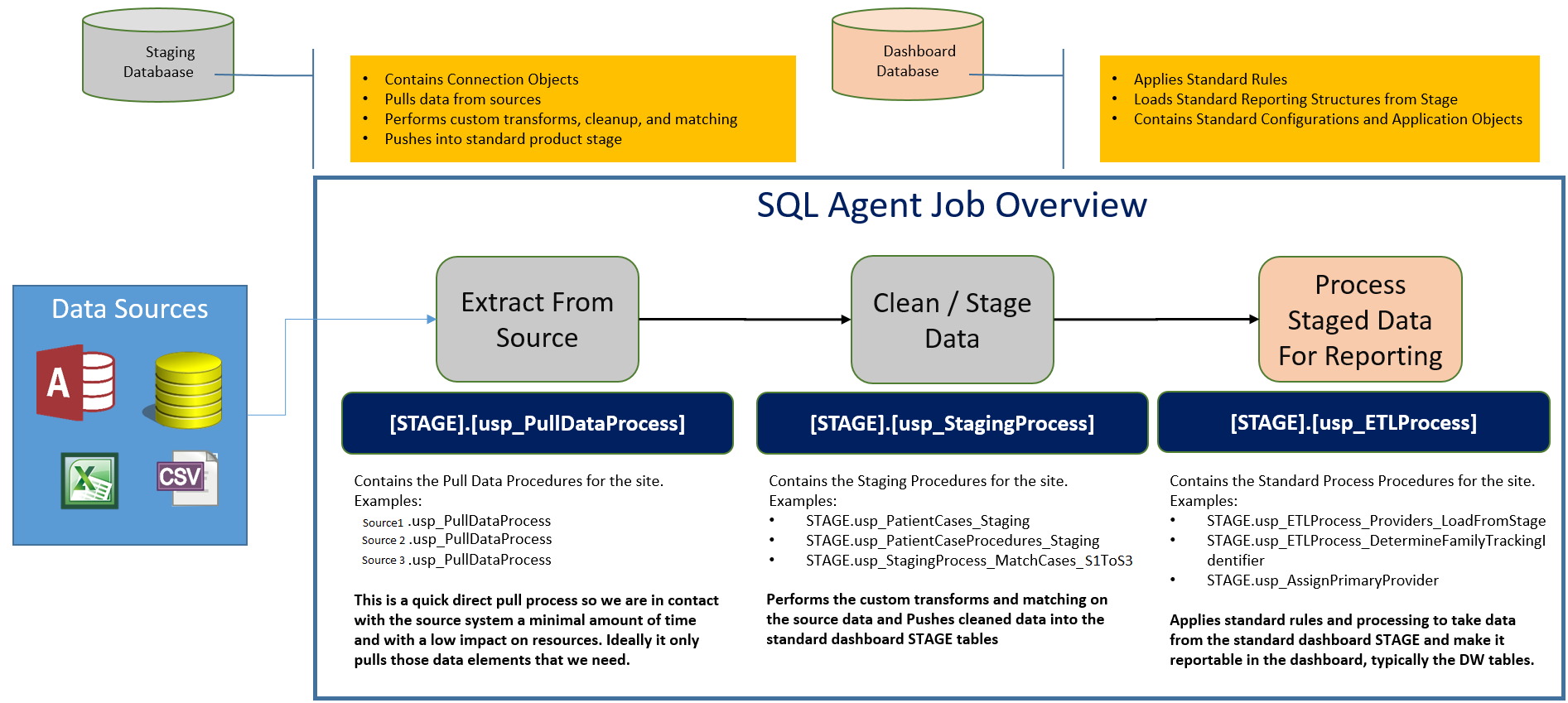
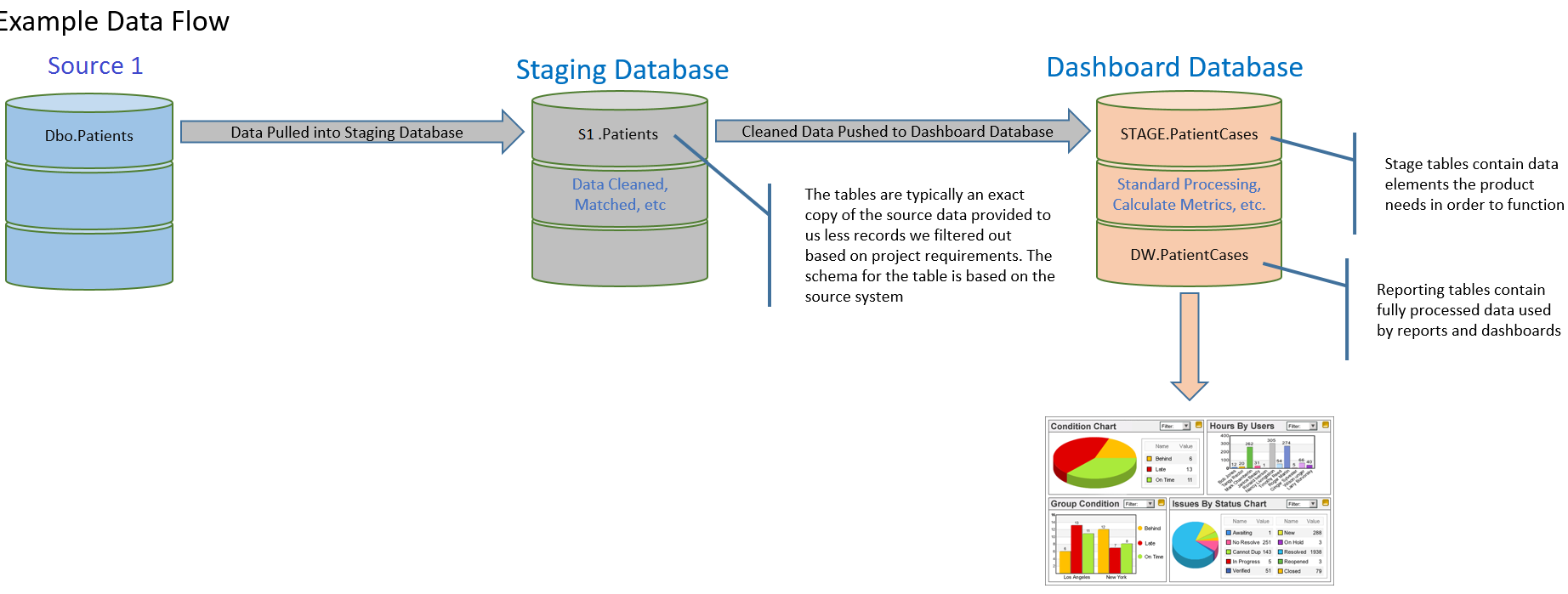
During deployment it is also quite common for the analyst implementing the software to want to understand the flow of data through the tool. While each site may have a different custom ETL solution, due to different data sources or just by using the source systems in different ways, below is a fairly consistent pattern we use.
What have your experiences been with on-site deployments so far? What is working well and what are still pain points?
Let us know in the comments below.