Someone recently read a post by Erik Darling over at BrentOzar.com titled Is it ever worth adding indexes to table variables. They were a little confused by the post and asked me about it.
I thought I would break it down here using the same structures Erik outlined. In his post he creates two table variables where the only difference is that one of them had a primary key specified on it. This is a significant difference that can impact query results, but for showing the SQL Optimizer join simplification it is ideal.
First, let’s look at the table without the primary key
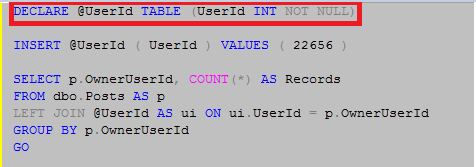
As no constraints are specified on our table variable it could contain multiple rows for every UserId, and since we are asking for a count of all records returned the optimizer needs to evaluate and assess what is in our table variable in order to give us the correct count.
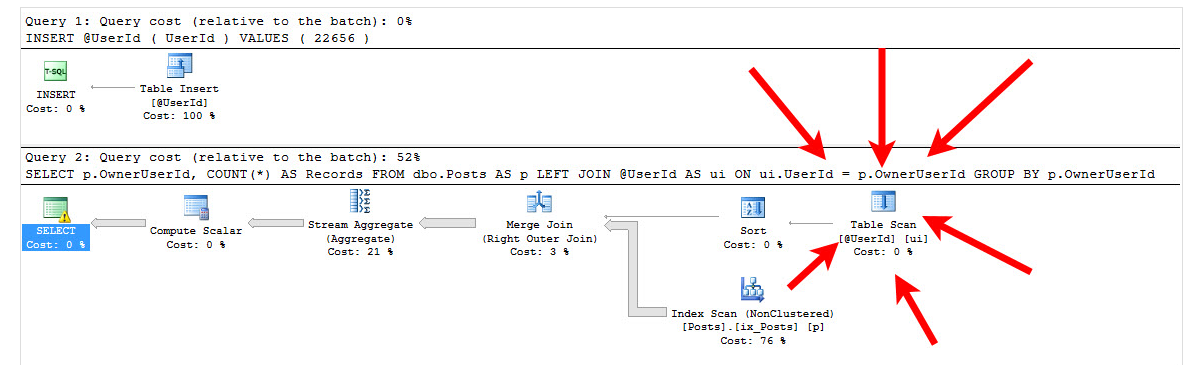
This gives an execution plan as such.
Now, let’s consider the table with a primary key
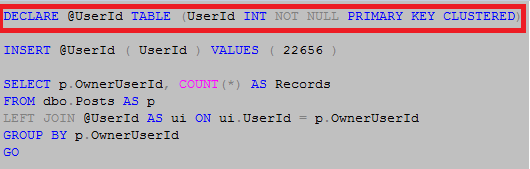
In this instance we know that our table variable cannot have more than 1 record per UserId, and since we are LEFT OUTER JOINING to the table variable on UserId the optimizer realizes that it does not even need to look at that table at all and removes it from the execution plan as we see here.
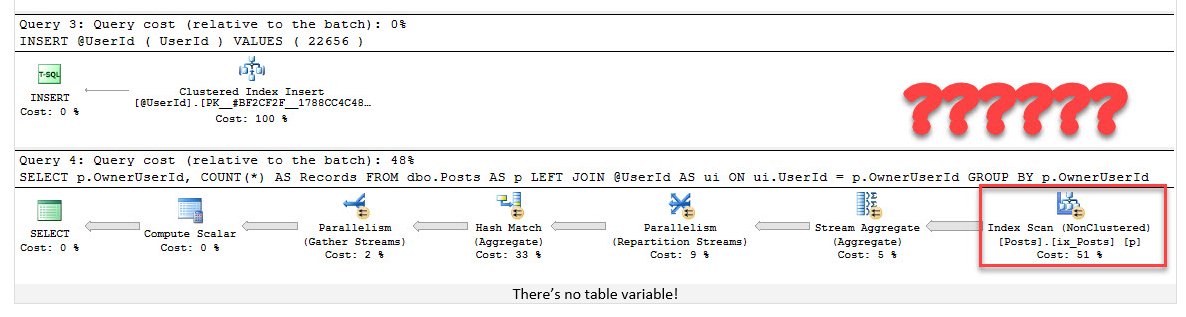
The optimizer in essence turned it into the simpler equivalent statement that follows and that we would have hopefully recommended during a code review.
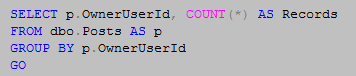
Obviously, if this had been an inner join the table variable would have been needed to assist the optimizer in filtering to only those UserId values present in both tables.
This is one of the reasons understanding the data model and constraints is important. In many cases the optimizer helps us out, but in other cases there is nothing it can do and we have to give it as much information as possible.
Did you find this interesting?
Let us know in the comments below.